



















For analyzing sentiment and competitors, safeguarding their online image, or tracking down influencers, businesses use Facebook data. With the proper equipment and understanding, data collection might become more accessible on the platform because of IP restrictions and rate throttling.

You will discover legal process of Facebook Data Scraping in this post, along with the tools you will need for a huge success rate and advice on avoiding IP address bans. We will also show you how to scrape Facebook pages utilizing a Python-based scraper in practice.
Defining Facebook Scraping
Facebook data scraping is a technique for gathering data from social networking platforms. One can use web scraping tools to extract Facebook data. The gathered data is cleaned up and exported in a format that is simple to study, like JSON.
Businesses can get client feedback, identify market trends, track their competitors’ online branding activities, and safeguard their reputation by scraping data points like posts, likes, and followers.
Is it Legal to Scrape Facebook Data?
Web scraping is legal even if social media networks may reject it when people grab publicly accessible data. The Ninth Circuit Court of Appeals determined in 2022 that the Computer Fraud and Abuse Act does not apply to scrape public data.
According to the cases Meta, the company that owns Facebook, has brought against data scrapers shortly after the latest judgment, that doesn’t stop it from vigorously combating anyone who uses its platforms to steal data. And it appears that Meta will keep fighting to maintain its monopoly on information.
What Kind of Data Can You Extract from Facebook?
The most popular Facebook categories are listed below.
Profiles provide the following public information:
Username, profile Photo URL, followers and followings, interests and likes, Profile URL and recently posted items.
Media URLs, likes, comments, texts, views, locations, dates, and the latest postings are all included in the posts.
Hashtags: post author ID, media URL, and Post URL.
URL, profile picture, name, number of likes, stories, followers, contacts, websites, categories, username, avatars, types, verified, and linked pages data for Facebook company pages.
Coding:
Required Tools for Facebook Scraping
You will require a headless browser library and a proxy server for the scraper to function.
Facebook uses a variety of tactics to combat scrapers, including blocking IP addresses and reducing request volume. By concealing your IP address and location, a proxy can assist you in avoiding this result. We’ve compiled a list of the top Facebook proxy services you will need help finding where to look for high-quality IPs.
For two reasons, we’ll need a headless browser. It will first assist us in loading dynamic content. Second, we can imitate an accurate browser fingerprint because Facebook utilizes anti-bot protection.
Managing Expectations
You should be aware of a few things before learning the code.
The Facebook data scraper supports only publicly accessible data. Although we don’t advocate scraping information that requires logging in, many will find this a drawback.
Facebook has done some changes that affect the scraper we’ll be employing. You must modify the scraper files to scrape several pages or eliminate the cookie consent prompt.
Preliminaries
You must include Python and the JSON library before we can begin. Install Facebook page-scraper after that. You can accomplish this by entering the command pip install into the terminal:
pip install facebook-page-scraper
Code Alterations
Let’s now make some modifications to the data scraper files.
- It would help if you changed the driver_utilities.py file to eliminate the cookie consent popup. Otherwise, the prompt will keep scrolling, and the scraper won’t produce any results.
pip install facebook_page_scraper
- To locate the files, use the console’s display command. Upon receiving the directory, you will be able to save the files.
allow_span = driver.find_element( By.XPATH, '//div[contains(@aria-label, "Allow")]/../following- sibling::div') allow_span.click()
The Entire Code will be:
@staticmethod
def ___wait_for_element_to_appear (driver, layout): ""expects driver's instance, wait for posts to show.
post's css class name is usercontentwrapper
try:
if layout == "old":
# wait for page to load so posts are visible
body = driver.find_element(By.CSS_SELECTOR, "body")
for in range(randint(3, 5)):
body.send_keys(Keys.PAGE_DOWN)
WebDriverwait(driver,
30).until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '.usercontentwrapper')))
elif layout == "new":
WebDriverWait(driver, 30).until(
EC.presence_of_element_located ((By.CSS_SELECTOR, "[aria-
posinset]")))
except WebDriverException:
# if it was not found, it means either page is not loading or it
does not exists
print("No posts were found!") Utilities.__close_driver(driver)
# exit the program, because if posts does not exists, we cannot go
further
sys.exit(1)
except Exception as ex:
print("error at wait_for_element_to_appear method :
{}".format(ex))
Utilities._close_driver (driver)
allow_span = driver.find_element(
By.XPATH, '//div[contains(@aria-label, "Allow")]/../following-
sibling::div')
allow_span.click()
- The scraper.py file needs to be changed if you want to scrape numerous pages at once. This upgrade will divide data from various scraping targets into separate files.
Init() should include the following lines. Additionally, to initialize these variables, add the self—parameter to the start of those lines.
_data_dict {} = and extracted_post = set()
File Demo after Corrections
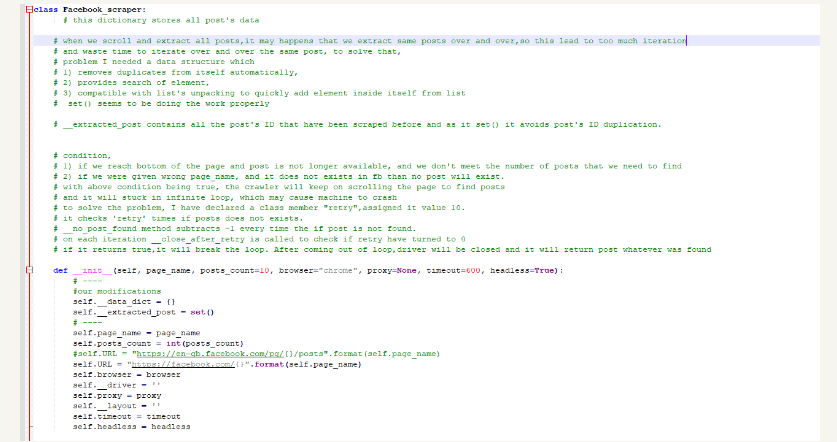
Steps to Extract Facebook Posts
Here is a real-world example using Selenium and residential proxy servers. Because Facebook can recognize and ban data center IPs, we are using residential addresses instead.
Step 1: Make a new text file and rename it facebook1.py in the directory of your choice. Open the documents and begin to write the main code after that.
- Bring in the Scraper
from facebook_page_scraper import Facebook_scraper
2. After that, pick the pages you wish to extract. For eg. select a few open profiles and enter their string values. Alternatively, you might scrape one page at a time.
page_list = ['KimKardashian','arnold','joebiden','eminem',''SmoshGames','Metallica','cnn']
Step 2: Let’s set our proxies and headless browser in step 2 now.
- Assign a numerical value to a variable for a proxy port. While you can utilize any revolving residentials or mobile proxy service, we’ll stay with Scraping Intelligence’s IP pool today.
proxy_port = 10001
- In the posts count variable, you should mention the number of post you wish to scrape.
posts_count = 100
3. Next, identify the browser. Firefox or Google Chrome are both acceptable choices depending on personal preference.
browser = "firefox"
4. Following a predetermined amount of inactivity, the timeout variable will stop scraping. When allocating it, use seconds as the unit of time. Although 600 seconds is the norm, you can change it to suit your needs.
timeout = 600
5. The headless browsers variable is next. If you wish to check the scraper, use false as a Boolean. If not, enter true and execute the program in the background.
headless = False
Step 3: Let’s execute the scraper now. Put your username and password in the proxy variable section if your proxy service demands it. Separate with a colon.
for page in page_list: proxy f'username: password@us.smartproxy.com: {proxy_port}'
Initialize the scraper after that. The page title, number of posts, type of browser, and other variables are passed as function arguments here.
scraper = Facebook_scraper (page, posts_count, browser, proxy=proxy, timeout=timeout, headless-headless)
Step 4: There are two methods to present the results. Choose one and enter the script.
- The console window displays the result of scraping. You’ll need JSON for this. Write the lines that follow.
json_data = scraper.scrap_to_json() print(json_data)
Develop a folder called facebook_scrape_results or whatever suits you, and leave it as a directory variable if you wish to export it as a CSV file.
directory = "C:\\facebook_scrape_results"
- Data from every Facebook page will then be saved in a file with a corresponding title in the two following lines.
filename = page scraper.scrap_to_csv(filename, directory)
Add code for proxy rotation, which will change your IP after every session to any technique. You won’t be subject to IP bans if you do this. Changing the session ID may be necessary with other providers; in our instance, it involves iterating the port number.
proxy_port += 1
Run the code on your terminal after saving it. In a few seconds, the results will appear on the screen.
Add code for proxy rotation, which will change your IP after each session to any technique. You won’t be subject to IP bans if you do this. Changing the session ID may be necessary with other providers; in our instance, it involves iterating the port number.
from facebook_page from facebook_page_scraper import Facebook_scraper
page_list = ['KimKardashian','arnold','joebiden','eminem','smosh','SmoshGames','ibis','Metallica','cnn']
proxy_port = 10001
posts_count = 100
browser = "firefox"
timeout = 600 #600 seconds
headless = False
# Dir for output if we scrape directly to CSV
# Make sure to create this folder
directory = "C:\\facebook_scrape_results"
for page in page_list:
#our proxy for this scrape
proxy = f'username:password@us.smartproxy.com:{proxy_port}'
#initializing a scraper
scraper = Facebook_scraper(page, posts_count, browser, proxy=proxy, timeout=timeout, headless=headless)
#Running the scraper in two ways:
# 1
# Scraping and printing out the result into the console window:
# json_data = scraper.scrap_to_json()
# print(json_data)
# 2
# Scraping and writing into output CSV file:
filename = page
scraper.scrap_to_csv(filename, directory)
# Rotating our proxy to the next port so we could get a new IP and avoid blocks
proxy_port += 1
For any Facebook data scraping services, contact Scraping Intelligence today!
Request for a quote!
Read More Article: Aspiring data scientists are in love with Python!




")

 – Bangla Typing Software Download")
")




